Where top-down design collides with bottom-up implementation
The tendency to underestimate FPGA development efforts based on IP availability and reuse.
Let us look at an example case study, beginning at the kickoff meeting for a new FPGA development effort. The algorithm team has spent months perfecting a system of software and models, and it is now time to turn this into a real-time embedded hardware realization. The lead system engineer puts up a slide in a language the engineers all understand - the system block diagram. The architecture looks amazingly simple.
Let us look at an example case study, beginning at the kickoff meeting for a new FPGA development effort. The algorithm team has spent months perfecting a system of software and models, and it is now time to turn this into a real-time embedded hardware realization. The lead system engineer puts up a slide in a language the engineers all understand - the system block diagram. The architecture looks amazingly simple.
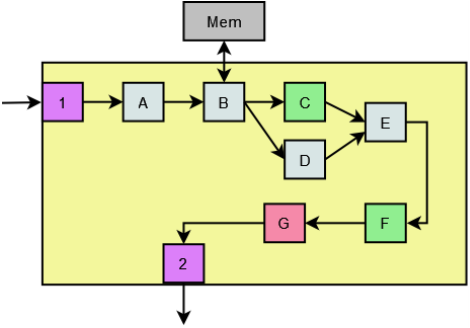
Overheard are a few salient comments... "Blocks A, B, D and E can use free IP cores." "We can reuse IP from a couple projects ago for Blocks C and F. C was fixed point and F was floating point, so we'll just need to do a couple conversions." "Interface 1 looks just like the one Bob worked on." "We can add the host interaction to Interface 2." "The only thing we'll really even need to develop is Block G." "I think we could even have a working prototype in 3 weeks."
Do these comments sound familiar? For reasons (usually) beyond engineer incompetence, FPGA development cycles are commonly underestimated. The simplistic, easy-to-follow nature of the block diagram combined with the semblance of all the building blocks being fully developed and "playing nice" together perpetuates the notion that modern FPGA designs are virtually plug-and-play. While continuous tool and IP improvement have led to dramatic increase in productivity per transistor implemented, design complexities and densities have increased right alongside, and the impact on the overall effort required is largely a wash. The black boxes are just bigger, with more going on under the hood and more logic fitting onto a single device. The following is a look at some of the problems encountered when an otherwise top-down design meets bottom-up implementation due to IP reuse.
Do these comments sound familiar? For reasons (usually) beyond engineer incompetence, FPGA development cycles are commonly underestimated. The simplistic, easy-to-follow nature of the block diagram combined with the semblance of all the building blocks being fully developed and "playing nice" together perpetuates the notion that modern FPGA designs are virtually plug-and-play. While continuous tool and IP improvement have led to dramatic increase in productivity per transistor implemented, design complexities and densities have increased right alongside, and the impact on the overall effort required is largely a wash. The black boxes are just bigger, with more going on under the hood and more logic fitting onto a single device. The following is a look at some of the problems encountered when an otherwise top-down design meets bottom-up implementation due to IP reuse.
IP Core Selection
Intellectual Property cores, whether royalty-free or purchased, are usually moderately well documented and verified in terms of size, performance and internal/interface operation. But in a bottom-up implementation, the deeper issues lie mainly in how well the cores will operate together in the system. Will the core interfaces support continuous full throughput on its input and/or output, and if not, will the throttling mechanism require complicated glue or closed loop control, extra FIFOs or multiple buffering? Are the data formats compatible between the design's cores with negligible effort, especially considering fixed and floating point conflicts? Will the cores scale to meet the needs of future spirals of the design, in either FPGA or ASIC? Because so much is hidden under the hood of an IP core black box, minute details can have a huge impact in a system context.
Legacy Design Reuse
The desire for design reuse sometimes creates what could qualify as an obsession with not reinventing the wheel. If code exists, no matter what the condition of the code or whether or not the original developers and/or documentation exist for support, someone will lobby to reuse it. It is indeed hard to predict up front the effort that will be required to reuse a legacy core compared to designing new, but the ease in which a legacy design can be modified tends to be greatly exaggerated. So will there be a cost benefit to reusing the legacy design? Will it require reverse engineering to add or remove capabilities, or to sever the design at clearly defined interfaces? Was the design verified in depth as it operated before and as it will operate now, with today's technology? Every case is different, but proceed with extreme caution with legacy designs.
Glue, Shims and System State
With an assembly of disjuncted cores comes the need to shim or to glue them all together. These extra logic layers range in complexity from simple data or control bit translations, to simple state machines to alter control sequences, to full blown complex controllers that monitor and propagate system state information through the subsystems. An oft-overlooked area is the control path, whereby a more intelligent device such as a system CPU will poke, peek and orchestrate the operation of the device. Reused IP cores may have little or no programmability, yet are required to conform to very predictable behavior in the system. Cores with more programmability must be configured in the proper manner at the proper time, and must have the different behaviors verified in the system context. Host interface and state explosion impact is easy to underestimate.
Overall Integration
Recall that this was a top-down design. System requirements have been flowed down to result in this specification, this device, this architecture. The bottom-up implementation may not result in what would have been the optimal top-down design, but as long as the sum of the parts achieves the required system performance under the given constraints on-time and on-budget, the design is a success. A deep understanding up front of how these trade-offs will affect the implementation will determine this outcome.
At Dillon Engineering, we believe our customers deserve practical and efficient designs at good value. Our existing and parameterized IP cores are well-documented, scalable and flexible, but where 3rd-party IP is the best solution, that is what we will use. Our experience and breadth of industries serviced allows us to sniff out the low-level behaviors that would become system issues. And our rigorous modeling and simulation processes ensure all configuration and data options are verfiied. When flowing down your design requirements, count on us to deliver optimal solutions on all fronts.
